
Implementation of Symbol Table in Compiler Design Tutorial with Examples
Symbol Tables
Symbol table is a data structure meant to collect information about names appearing in the source program. It keeps track about the scope/binding information about names. Each entry in the symbol table has a pair of the form (name and information).
- Information consists of attributes (e.g., type, location) depending on the
- Whenever a name is encountered, it is checked in the symbol taL to see. if already occurs. If not, a new entry is created.
In some cases, the symbol table record is created by the lexical analyzer as soon as the name is encountered in the input and the attribute of the name are entered when the declarations are processed.
If same name can be used to denote different program elements in same block, the symbol table record is created only when the name semantic role is discovered.
Operations on Symbol Table
- Determine whether a given name k in the table.
- Add a new name the table.
- Access information associated to a given name.
- Add a new information on for a given name.
- Delete a name or group of names) from the table.
Implementation of Symbol Table
- Each entry in a symbol table can be implemented as a record that consists of several field.
- The entries in symbol table records are not uniform and depend cry the program element identified by the name.
- Some information about the name may be kept outside of the symbol table record and/or some fields of the record may be left vacant for the reason of uniform A pointer to this information may be stored in the record.
- The name may be stored in symbol table record it self or it can be stored in a separate array of characters and a pointer to it in the symbol table
- The information about runtime storage location, to be used at the time of code generation, is to kept in the symbol table.
- Various approaches to symbol table organisation g., linear list, search tree and hash table.
Linear List
- It is the simplest approach in symbol table organisation.
- The new names are added to the table in order they arrive.
- A name is searched for its existence linearly.
KEY Points
- The average number of comparisons required in a linear list are proportional to 0.5 * (n + 1) where n=number of entries in the table..
- It take less space but more access time.
- The time for adding/searching a name in search tree is proportional to (m+n) log2
- The hash function maps the name into an integer value between 0 and k-1 and uses it as an index in the hash table to search the list of the table records that are built on that hash index.
Search Tree
- It is more efficient than linear lists.
- We provide two links left and right, which point to record in the search tree.
- A new name is added at a proper location in the tree such that it can be accessed alphabetically.
- For any node A1 in the tree, all nodes accessible by the following left link precede node A1 alphabetically.
- Similarly, for any node A1 in the tree, all names accessible by the following right link succeed A1 alphabetically.
Hash Table
- A hash table is a table of k-pointers from 0 to k-1 that point to the symbol
table and record within the symbol table.
- To search a value, we find out the hash value of the name
suitable hash function.
- To add a non-existent name, we create a record for that name and insert it at the head of the list.
Code Optimization
It refers to obtain a more efficient code. While performing optimization, there are
points, which we need to focus on.
- We must ensure that the transformed program is semantically equivalent to the original program.
- The improvement of the program efficiency must be achieved without changing the algorithms which are used in the program.
Techniques used in Optimization
The following are the techniques used in optimization as
Common Sub-expression Elimination
An expression need not be evaluated, if it was previously computed and values of variables in this expression have not changed, since the earlier computations.
e.g., a= b*c;
d=b*c+x-y;
We can eliminated the 2nd evaluation of b k c from this code if none of intervening statements has changed its value. So, we can rewrite the above code as
T1=b*c;
a =T1;
d =T1+ x- y;
Compile Time Evaluation
We can improve the execution of a program by shifting execution time actions to compile time.
- eg. A=2*(22.0 / 7.0)*r
,
Here, we can perform the computation 2*(22.01 7.0) at compile time itself. This is known as folding.
Using Constant Propagation
Optimized
x=12.4 —-> y=12.4/2.3
code
In the above example y can directly be computed at compile time. If a variable is assigned a constant value and is used in & expression without being assigned other value to it, we can evaluate some portion of the expression using the constant value.
Using Variable Propagation
If a variable is assigned to another variable, we use one in place of another. This will be useful to carry out other optimisation that were that were otherwise not possible.
e.g.,
In the above example, if we replace x by a then, a • b and x*b will be identified as common sub-expressions.
Using Dead Code Elimination
It the value contained in a variable at that point is not used anywhere in the Program subsequently, the variable is said to be (lead at that place Variable Propagation often leads to making assignment statement into dead code.

Using Code Motion
Evaluation Of expression is moved from one part of the program to another in such a way that it If is evaluated leaser frequently,
We can bring the loop-invariant statement out of the loops.

Using Induction Variable and Strength Reduction
An induction variable may be defined as an integer scalar variable which is used in loop for the following kind of assignments i.e., i = i + constant. Strength reduction refers to the replacing the high strength operator by a low strength operator. Strength reduction used on induction variables to achieve a more efficient code.
e.g. 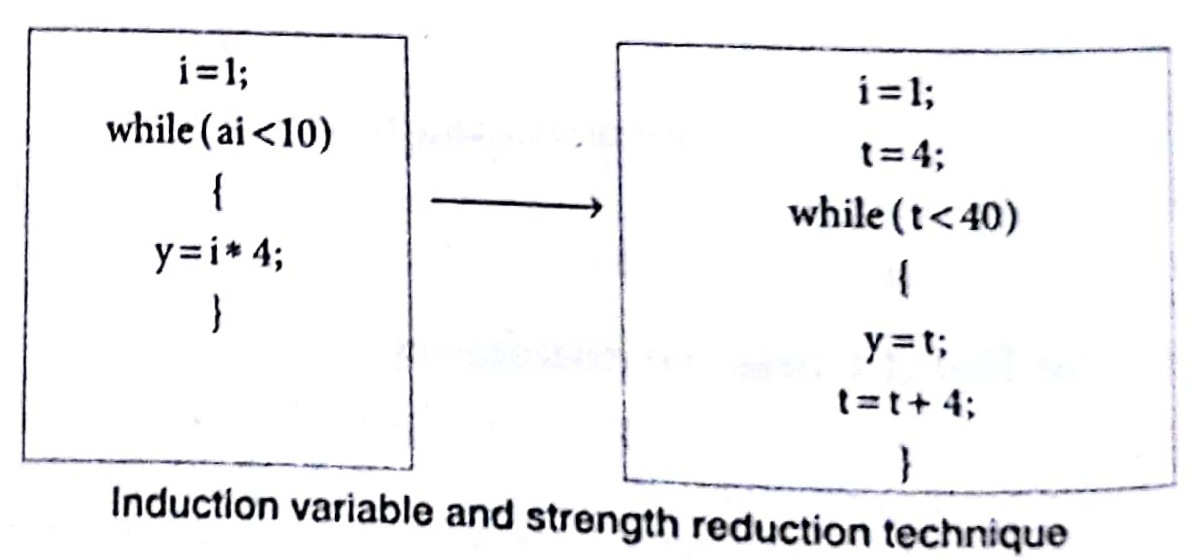
Use of Algebraic Identities
Certain computations that look different to the compiler and are not identified as common sub-expressions are actually same. An expression Bop C will usually be treated as being different to Cop B. But for certain operations (like addition and multiplication), they will produce the same result. We can achieve further optimization by treating them as common sub-expressions for such operations.
Run-Time Administration
It refers how do we allocate the space for the generated target code and the data object of our source programs? The places of the data objects that can be determined to compile time will be allocated statically. But the places for the some of data objects will be allocated at run-time.
The allocation and deallocation of the data objects is managed by the run-time support package. Run-time support package is loaded together with the generated target code. The structure of the run-time support package depends on the semantics of the programming language (especially the semantics of procedures in that language).
Procedure Activation
Each activation of a procedure is called as activation of that procedure. An execution of a procedure starts at the beginning of the procedure body. When the procedure is completed, it returns the control to the point immediately after the place, where that procedure is called. Each execution of the procedure is called as its activation.
- Lifetime of an activation of that procedure (including the other procedures called by that procedure).
- If a and b are procedure activation, then their lifetimes are either non–overlapping or are nested.
- If a procedure is recursive, a new activation can begin before an earlier activation of the same procedure has ended.
Sorting in Design and Analysis of Algorithm Study Notes with Example
Learn Sorting in Handbook Series: Click here
Follow Us on Social Platforms to get Updated : twiter, facebook, Google Plus