
Scheduling Algorithm in Operating System Study Notes with Examples
Schedulers
A process migrates among various scheduling queues throughout its lifetime. The OS must select for scheduling purposes, processes from these queues in some fashion. The selection process is carried out by the appropriate scheduler.
Long Term and Short Term Schedulers
- A long term scheduler or job scheduler selects processes from job pool (mass storage device, where processes are kept for later execution) and loads them into memory for execution.
- A short term scheduler or CPU scheduler, selects from the main memory among the processes that are ready to execute and allocates the CPU to one of them
- The long term scheduler controls the degree of multiprogramming (the number of processes in memory).
Note: Mid-term scheduler uses the concept of swapping.
Dispatcher
It is the module that gives control of the CPU to the Process selected by the shatt scheduler. This function involves the following
- Switching Context
- Switching to user mode
- Jumping to the proper location in the user program to restart that program
Scheduling Algorithm
All of the processes which are ready to execute and are placed in main memory then selection of one of those processes is known as scheduling. And after selection that process gets the control of CPU.
Scheduling Criteria
The criteria for comparing CPU scheduling algorithms include the following
CPU Utilization: Means keeping the CPU as busy as possible.
Throughput: It is nothing but the measure of work i.e., the number of processes that are completed per time unit.
Turnaround Time: The interval from the time of submission of a process to the time of completion. It is the sum of the periods spent waiting to get into memory, waiting in the ready queue, executing on the CPU and doing I/O.
Waiting Time: The sum of the periods spent waiting in the ready queue.
Response Time The time from the submission of a request until the first response is produced.
Key Points
- The amount of time, a process takes to start responding not the time it takes to output the response is called response time.
- Response time is desirable to maximize CPU utilization and throughput and to minimize turnaround time, waiting time and response time.
There are many CPU scheduling algorithms as given below
First Come First Served (FCFS) Scheduling
With this scheme, the process that requests the CPU first is allocated the CPU first. The implementation of the FCFS policy is easily managed with FIFO queue. When a process enters the ready queue, its PCB (Process control Block) is linked onto the tail of the queue. When the CPU is free, it is allocated to the process at the head of the queue. The running process is then removed from the queue.
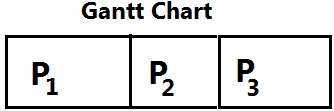
0 24 27 30
Waiting time for P1 = 0 ms
Waiting time for P2 = 24 ms
Waiting time for P3 = 27 ms
Average waiting time

Turn around time for P1 = 24 – 0 = 24 ms
Turn around time for P2 = 27 — 24 :23 ms
Shortest Job First (SJF) Scheduling
When the CPU is available, it is assigned to the process that has the smallest next CPU burst. If the two processes have the same length or amount of next CPU burst, FCFS scheduling is used to break the tie.

Waiting Time for P1 = 3
Waiting Time for P2 = 16
Waiting Time for P3 = 9
Waiting Time for P4 = 0
A more appropriate term for this scheduling method would be the shortest. next CPU burst algorithm because scheduling depends on the length of the next CPU burst of a process rather than its total length.
Preemptive and Non-preemptive Algorithm
The SJF algorithm can either be preemptive or non-preemptive. The choices arises when a new process arrives at the ready queue while a Previous process is still executing. The next CPU burst of the newly arrived Process may be shorter than what is left of the currently executing process.
A preemptive SJF algorithm will preempt the currently executing process Whereas a non-preemptive algorithm will allow the currently running process to finish its CPU burst. Preemptive SJF scheduling is sometimes called shortest-remaining-time-first-scheduling.
Process Table
| Process | Arrival Time | Burst Time |
| P1 | 0 | 8 |
| P2 | 1 | 4 |
| P3 | 2 | 9 |
| P4 | 3 | 5 |
Waiting time for P1 = (10 — 1) = 9
Waiting time for P2 = ( 1 – 1) = 0
Waiting time for P3 =17 — 2 =15
Waiting time for P4 = 5 — 3 = 2
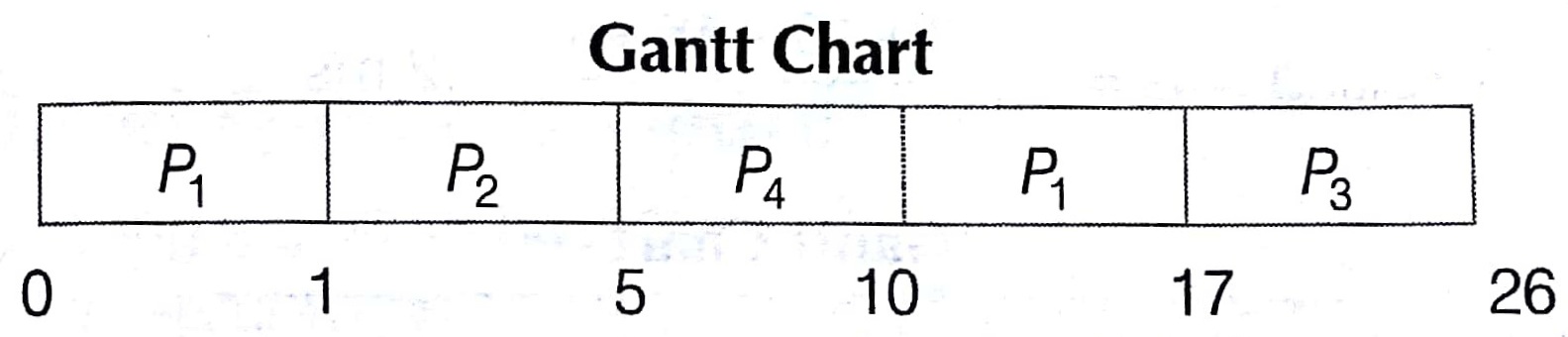
Average waiting time = 9 + 0 + 15 + 2 = 6.5 ms
4
Priority Scheduling
A priority is associated with each process and the CPU is allocated to the process with the highest priority. Equal priority processes are scheduled in FCFS order.
We can be provided that low numbers represent high priority or low numbers represent low priority. According to the question, we need to assume any one of the above.
Key points
- Priority scheduling can be either preemptive or non-preemptive.
- A preemptive priority scheduling algorithm will preempt the CPU, if the priority of the newly arrived process is higher than the priority of the currently running process.
- A non-preemptive priority scheduling algorithm will simply put the new process at the head of the ready queue.
A major problem with priority scheduling algorithm is indefinite blocking or starvation

.Waiting time for P1 = 6
Waiting time for P2 = 0
Waiting time for P3 =16
Waiting time for P4 =18
Waiting time for P5 =1
Average waiting time = 6 + 0 + 16 + 18 + 1 = 8.2 ms
5

Round Robin (RR) Scheduling
The RR scheduling algorithm is designed especially for time sharing systems. It is similar to FCFS scheduling but preemption is added to switch between processes. A small unit of time called a time quantum or time slice is defined.
The ready queue is treated as a circular queue. The CPU scheduler goes around the ready queue allocating the CPU to each process for a time interval of up to 1 time quantum. The process may have a CPU burst of less than 1 time quantum, in this case the process itself will release the CPU voluntarily. The scheduler will then proceed to next process in the ready queue.
Otherwise, if the CPU burst of the currently running process is longer than 1 time quantum, the time will go off and will cause an interrupt to the operating system. A context switch will be executed and the process will be put at the tail of the ready queue. The CPU scheduler will then select the next process in the ready queue.
Process Table
| Process | Burst Time (in milliseconds) |
| Pi | 24 |
| P2 | 3 |
| P3 | 3 |
Let’s take time quantum =4 ms. Then the resulting RR schedule is as follows
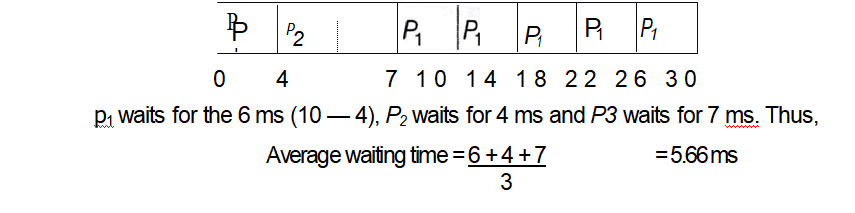 Multilevel Queue Scheduling
Multilevel Queue Scheduling
This scheduling algorithm has been created for saturation in which processes are easily classified into different groups. e.g., a division between foreground (interactive) processes and background (batch) processes. A multilevel queue scheduling algorithm partitions the ready queue into several separate queues. The processes are
permanently assigned to one queue, priority generally based on some property of
the process, such as memory size, process priority or process type.
Multilevel Feedback Queue Scheduling
This scheduling algorithm allows a process to move between queues. The .d ea is to separate processes according to the characteristics of their CPU bursts.
If process uses too much CPU time, it will be moved to a lower priority queue. Similarly, a process that waits too long in a lower priority queue may be moved to a higher priority queue. This form of aging prevents starvation.
Synchronization
When several processes access and manipulate the same Data concurrently and the outcome of the execution depends on the
the particular order in which the access takes place is race condition.
e.g., Suppose we have two variables A and B. The operation on A and B are as follows

For the race condition above, we need to ensure that only one process at time can be manipulating the variable result. To make such a guarantee we require that the processes be synchronized is some way.
inter-process Communication (IPC}
Processes executing concurrently in the operating system may be either independent or cooperating processes. A process is independent if it affect or be affected by the other processes executing in the system. Any process that shares data with other processes is a cooperating process. Advantages of process cooperation are information sharing, computation speed up, modularity and convenience to work on many task the same time. Cooperating processes require an Intel-Process communication (IPC) mechanism that will allow them to exchange data and information.
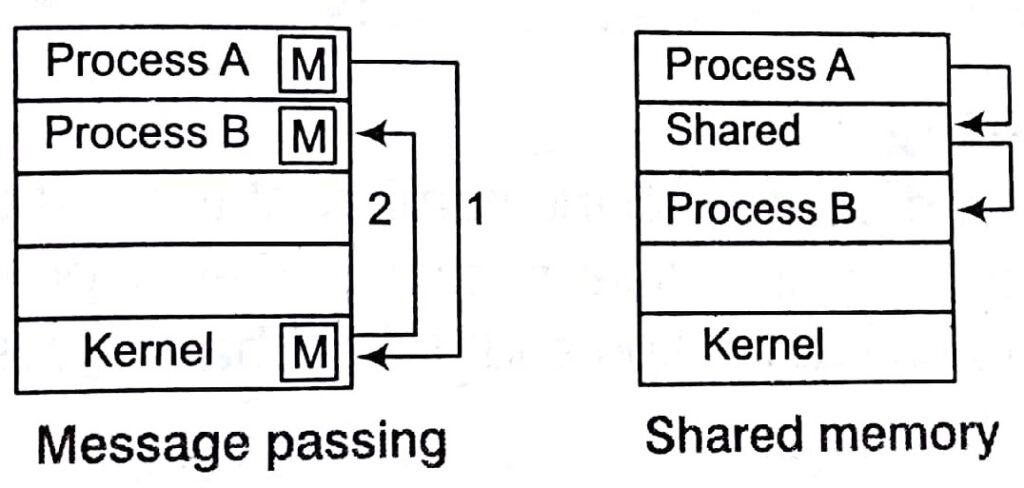
There are two fundamental models of IPC
(1) Shared memory (ii) Message passing
In the shared memory model, a region of memory that is shared by cooperating process is established. Process can then exchange information by reading and writing data to the shared region.
In the message passing model, communication takes place by means of messages exchanged between the cooperating processes.
The Critical Section Problem
Consider a system containing of n processes {P0, P1, • • • , Pn – 1}. Each process has a segment of code, called a critical section, in which the process may be changing common variables, updating a table, writing a file and so on.
The important feature of the system is that, when one process is executing in its critical section, no other process is to be allowed to execute in its critical section. That is, no two processes are executing in their critical sections at the same time.
- The critical section problem is to design a protocol that the processes can use to cooperate. Each process must request permission to enter its critical section.
- The section of code implementing this request is the entry The critical section may be followed by an exit section. The remaining co e remainder section.
General structure of a typical process Pi is given below do

A solution tO– critical section problem must satisfy the following three requirements .
Mutual Exclusion
If a process Pi is executing in its critical section, then no other processes can be executing in their critical sections.
Progress
If no process is executing in its critical section and some processes wish to enter their critical sections, then only those processes that are not executing in their remainder sections can participate in deciding which will enter its critical section next and this selection can’t be postponed indefinitely.
Bounded Waiting
There exists a bound or limit, on the number of times that other processes are allowed to enter their critical sections after a process has made a request to enter its critical section and before that request is granted.
Semaphores
Semaphore is nothing but a synchronization tool. A semaphore S is an integer variable that apart from initialization, is accessed only through two standard atomic operations wait ( ) and signal ( ). The wait ( ) operation does testing of the integer value of S (S < 0) as well as its possible modification (S — —).
wait (S)
while S < = 0
i ; / / no operation
S — —;
}
The signal() operation does increment to the integer value of S +jr
Signal(S)
}
S++;
}
All modifications to the integer value of semaphore in the wait ( ) and signal () operations must be executed indivisibly,
usage of Semaphores
- we can use binary semaphores to deal with the critical section problem for multiple processes. The n processes share a semaphore, mutex, initialized to 1.
- The value of binary semaphore can range only between 0 and 1,
- Binary semaphores are known as mutex locks as they are locks that provide mutual exclusion.
Mutual exclusion implementation with semaphores
do {
wait (mutex);
// Critical section
signal (mutex);
// Remainder section
) while (TRUE);
Key Points
- Counting semaphores can be used to control access to a given resource consisting of a finite number of instances.
- The value of a counting semaphore can range over an unrestricted domain.
Classical Problem of Process Synchronization
- Producer-consumer problem 2. Readers-writer problem 3. Dining-philosopher problem
producer-Consumer Problem
In this problem, there are two processes
(i) producer process (ii) consumer process.
A Shared buffer(global) is defined which is accessible by producer and consumer.
- producer process produces items and appends these in buffer.
- Consumer process consumes items from buffer.
The Readers-Writers Problem
Suppose that a database is to be shared among several concurrent processes. Some of these processes may want only to read the databases (we can say these as readers). Whereas other processes may want to update (that is to read and write) the database (we can say these processes as writers). Obviously, if two readers access the shared data simultaneously, no adverse effects will result.
- However, if a write and some other process (either a reader or a writer) access the database simultaneously, chaos may ensure.
- To ensure that these difficulties do not arise, we require that the writers have exclusive access to the shared database while writing to database.
- This synchronization problem is referred to as the readers-writers
Key Points
- Both of the processes (i.e., producer and consumer) cannot access buffer
- Mutual exclusion should be here.
- Producer cannot append item in full buffer (finite buffer) and consumer can not take item from empty buffer.
The Dining-Philosophers Problem
Consider five philosophers who spend their lives thinking and eating. The philosophers share a circular table surrounded by 5 chairs, each belonging to one philosopher. In the center of the table is a bowl of rice and the table is laid with 5 chopsticks. When a philosopher thinks, he doesn’t interact with his colleagues.
From time to time, a philosopher gets hungry and tries to pick up the 2 chopsticks that are closest to him (the chopsticks that are between him and his left and right neighbors). A philosopher may pick up only one chopstick at a time. Obviously, he can’t pick up a chopstick that is already in the hand of a neighbour. When a hungry philosopher has both his Chopsticks at the same time. He eats without releasing his chopsticks.When he is finished, he puts down both of his chopsticks and starts thinking again. This problem is a simple representation of the need to allocate several resource among several processes in a deadlock free and starvation free manner.
Sorting in Design and Analysis of Algorithm Study Notes with Example
Learn Sorting in Handbook Series: Click here
Follow Us on Social Platforms to get Updated : twiter, facebook, Google Plus